

长文档挑战赛:Qwen2-Plus-Latest 对阵 DeepSeek-V3,
一份10万字行业研究报告,两个当红大模型,一场关于长文档处理能力的终极对决——谁能以更低成本提供更优解决方案?
作为一名金融分析师,我每周都需要处理大量的行业研究报告。最近接到一份挑战性任务:分析一份长达10万字的半导体行业深度报告,需要从中提取核心观点、技术趋势分析以及投资建议。
这不仅要求模型具备强大的理解能力,更需要处理长文档的稳定性——毕竟,没有任何分析师愿意看到模型在处理到8万字时失忆或崩溃。这就是我决定对比Qwen2-Plus-Latest和DeepSeek-V3的初衷:找出真正的长上下文王者。
本次评测的两位选手都声称支持128K超长上下文,这相当于一次性处理约300页文档的能力,理论上完美匹配我的需求。
Qwen2-Plus-Latest:阿里云通义千问的最新力作,在多语言和综合能力方面享有盛誉,被许多企业级用户视为可靠选择。
DeepSeek-V3:深度求索公司推出的明星模型,以出色的代码能力和极致的性价比在开发者社区中快速获得认可。
两位选手都具备处理长文档的硬件条件,但真正的考验在于:在实际任务中,谁能更好地理解和分析超长内容?谁的性价比更高?
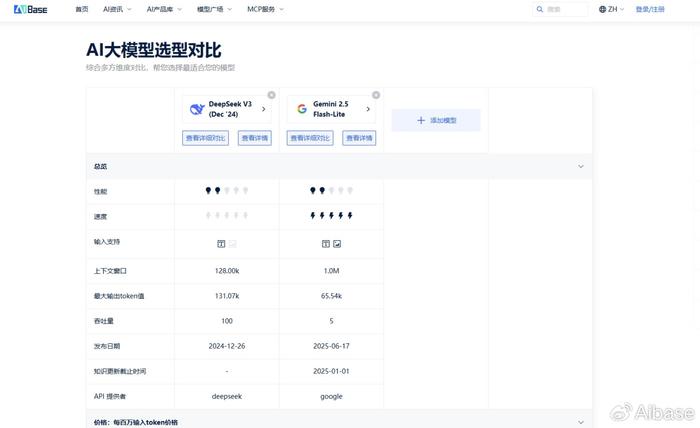
为确保评测的公正性和客观性,本次对比的所有基础数据均来自AIbase模型选型对比平台。这是一个提供多维度模型对比数据的第三方平台,帮助用户做出基于数据的理性决策。
结果表明:DeepSeek-V3的低于Qwen2-Plus-Latest。对于需要频繁处理长文档的用户来说,这种成本差异在规模化后将会产生巨大影响。
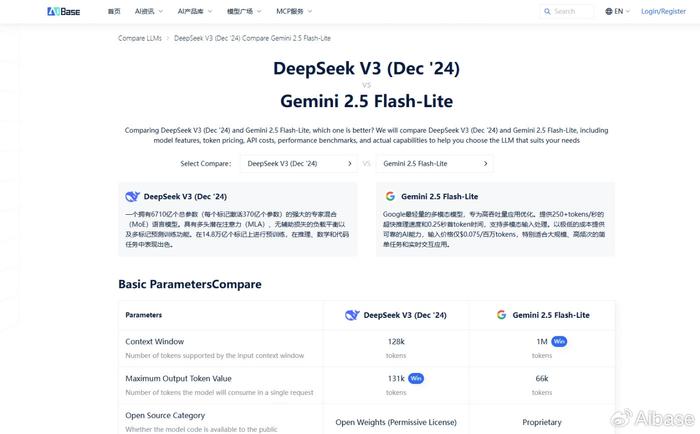
根据AIbase平台上的能力评分数据,我们可以对两个模型在长文档处理任务中的表现进行合理推测:
长上下文理解能力:两个模型在长上下文处理方面都获得了高分,这表明它们都能较好地维持长文档中的信息一致性。DeepSeek-V3在相关评测中稍占优势,这可能意味着在极端长度的文档处理中表现更加稳定。
摘要与信息提取能力:Qwen2-Plus-Latest在文本摘要任务中表现出色,其强大的语言理解能力可能帮助它更好地识别和提炼关键信息。特别是在处理涉及复杂概念和技术术语的行业报告时,这一优势可能更加明显。
DeepSeek-V3虽然在代码任务中表现突出,但其在文本理解和摘要任务中也获得了不错的评分,完全有能力处理金融文档分析任务。
推理与洞察生成:这是投资分析的关键环节。Qwen2-Plus-Latest在推理能力评分上略有优势,可能在进行趋势分析和投资建议生成时提供更深入的见解。
然而,重要的是注意到:评分差异并不巨大,两个模型都应该能够胜任基本的分析任务。对于大多数实际应用场景,这种细微的评分差异可能不会导致显著的效果区别。
极致性价比选择:DeepSeek-V3如果您的主要需求是低成本地处理大量长文档,进行基础的信息提取和摘要,DeepSeek-V3提供了近乎极致的性价比。其成本优势如此明显,以至于即使在某些能力维度上稍有不足,也完全可以通过成本优势来补偿。
能力优先选择:Qwen2-Plus-Latest如果您的任务对分析深度和洞察质量有极高要求,且成本不是首要考虑因素,Qwen2-Plus-Latest可能更适合。特别是在需要处理多语言文档或涉及复杂推理的任务中,其综合能力优势可能更加明显。
DeepSeek-V3在性价比方面建立了几乎无法超越的优势,特别适合预算敏感的大规模应用场景。而Qwen2-Plus-Latest则凭借其综合能力优势,在高质量分析任务中保持竞争力。
作为一名金融分析师,我个人的选择倾向是:对于日常的大量文档预处理和初步分析,使用DeepSeek-V3控制成本;对于最终的投资决策支持任务,则使用Qwen2-Plus-Latest确保分析质量。
我建议您也根据自己的具体需求deepseek,到AIbase模型选型对比平台()上进行亲自对比。只有基于您的特定场景和需求,才能做出最合适的模型选择决策。
毕竟,最好的模型不是评分最高的那个,而是最适合您具体需求的那个。在这个意义上,真正的上下文王者可能因任务而异,因人而异。原文出处:长文档挑战赛:Qwen2-Plus-Latest 对阵 DeepSeek-V3,谁才是真正的上,感谢原作者,侵权必删!

